Grounding DINO: A Breakthrough in Open-Set Object Detection
In the world of computer vision, the ability to detect objects in images has become ubiquitous. From self-driving cars to medical imaging, object detection is revolutionizing industries. But what if we could take it a step further and develop a system that can detect any object, even those it has never seen before?
That's the idea behind Grounding DINO, a new open-set object detector that is pushing the boundaries of what's possible in computer vision. Developed by researchers at Tsinghua University and IDEA, Grounding DINO is a significant leap forward in the field, with the potential to transform how we interact with the visual world.
What is Grounding DINO? Grounding DINO is an AI model that can detect and locate objects in an image, similar to other object detection models. But what sets it apart is its ability to detect objects even if they weren't explicitly included in its training data. This is known as open-set object detection.
Traditional object detectors are trained on a closed set of object categories. They can only detect objects from those specific categories they've been trained on. Grounding DINO, on the other hand, can generalize to new, unseen object categories.

The model achieves this by combining visual information from images with language inputs, such as category names or descriptive sentences. This allows Grounding DINO to understand the semantic meaning of objects, enabling it to detect objects it has never encountered before.
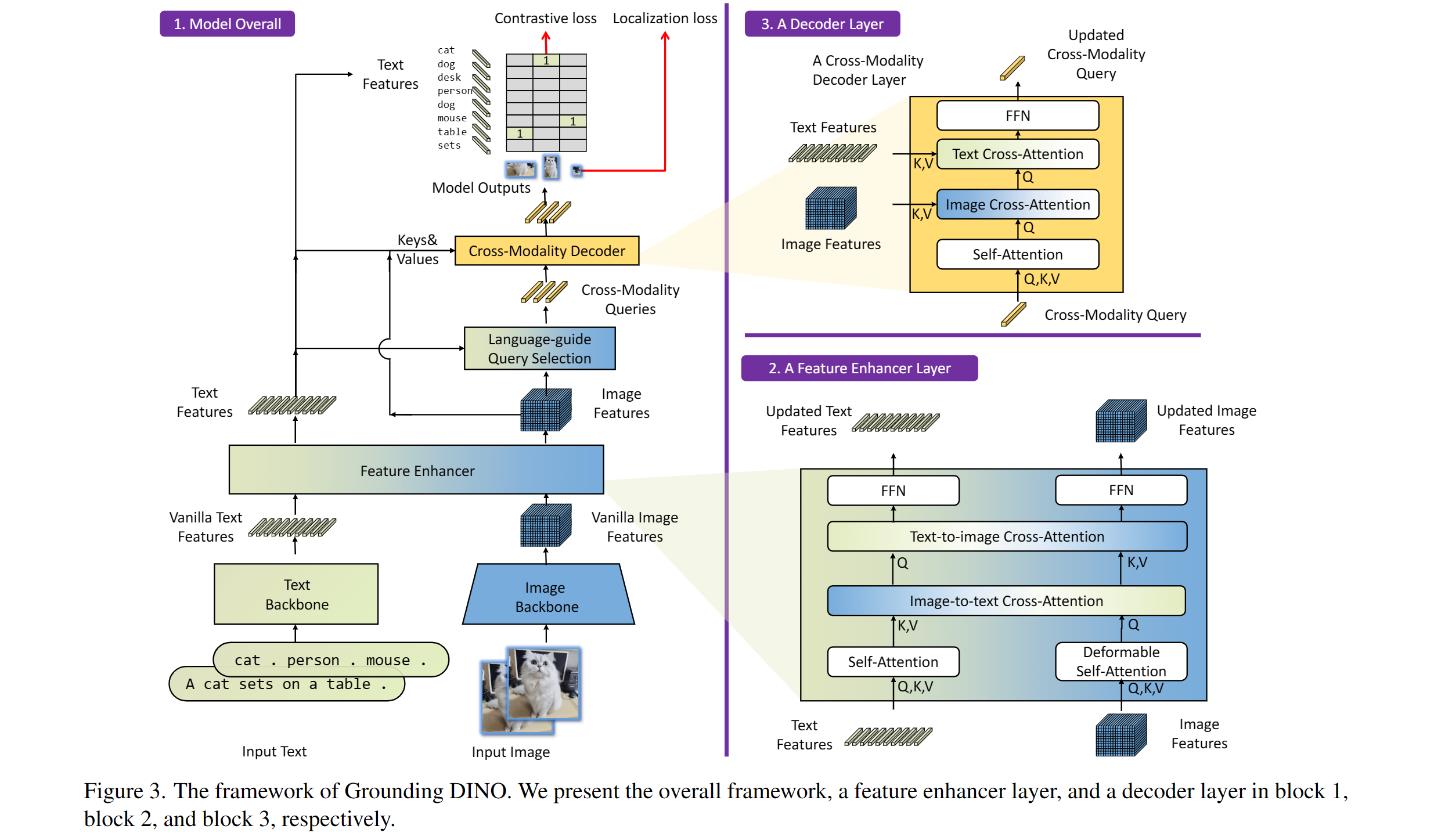
How Does Grounding DINO Work? Grounding DINO is built on top of DINO, a powerful Transformer-based object detector. The researchers enhanced DINO by incorporating several key innovations:
Tight Modality Fusion: Grounding DINO effectively fuses language and visual information by incorporating language inputs into various stages of the detection process. This ensures a strong connection between visual features and their corresponding language descriptions.
Large-Scale Grounded Pre-training: The model is pre-trained on massive datasets containing object detection data, grounding data (matching images with language phrases), and image captions. This extensive pre-training enables Grounding DINO to learn rich semantic representations and generalize to new concepts.
Sub-Sentence Level Text Feature: To further improve language understanding, Grounding DINO introduces a technique that utilizes sub-sentence level text features. This helps the model focus on individual words or phrases, reducing the influence of unrelated words in a sentence.
Why is Grounding DINO Important? Grounding DINO represents a significant advancement in object detection, with broad implications for various applications:
- Image Editing: Imagine being able to seamlessly add or remove objects from an image simply by providing text descriptions. Grounding DINO can be combined with image generation models to enable advanced image editing capabilities.
- Robotics: Robots equipped with Grounding DINO could understand and interact with their environment more effectively, enabling them to perform complex tasks in unstructured settings.
- Human-Computer Interaction: Grounding DINO could pave the way for more intuitive human-computer interaction, allowing users to communicate with computers using natural language to reference objects in images.
- Content Creation: Designers, artists, and content creators could use Grounding DINO to streamline their workflows, automating tasks such as image tagging, object removal, and content generation.
FYNDIT AI: Revolutionizing Object Detection in Everyday Life. The groundbreaking technology behind Grounding DINO has the potential to transform everyday life. At FYNDIT, we're developing an innovative solution to the age-old problem of losing or misplacing personal items.

.gif)
.gif)
Our cutting-edge tracking solution combines camera-based object detection, web applications, and voice processing to help users quickly locate their belongings. By leveraging the power of open-set object detection, FYNDIT AI can detect and track a wide range of items, even those it hasn't been specifically trained on.
Whether you're at home, in the office, or at an elderly care facility, FYNDIT AI provides a seamless and efficient way to keep track of your valuables. Our privacy-focused design ensures that your data remains secure, while our intuitive interface makes it easy for anyone to use.
Take Our User Stories Survey:
We're committed to building a product that truly solves the problem of misplaced items. Share your experiences and help us improve FYNDIT AI by taking our User Stories Survey.
Sign Up for Our Beta Release:
Be among the first to experience the future of object detection. Sign up for our beta release and help us shape the future of FYNDIT AI.
Share with Your Friends and Network.
Spread the word about FYNDIT AI and help us revolutionize how people keep track of their belongings.
Grounding DINO is a remarkable achievement in open-set object detection, opening up new possibilities for how we interact with the visual world. At FYNDIT AI, we're excited to harness the power of this technology in combination with our novel VISION algorithms to solve real-world problems and improve people's lives. Join us on this journey as we redefine the future of object detection.
.gif)

Comments
Post a Comment